隨著互聯網的快速發展,海量數據已成為各行各業的重要資源,簡單爬蟲架構作為數據采集的主要手段之一,在數據處理和存儲支持服務方面發揮著關鍵作用。本文將從核心技術、實現流程和優化策略等角度系統分析簡單爬蟲架構中數據處理與存儲支持服務的構建。
一、爬蟲架構與數據處理概述
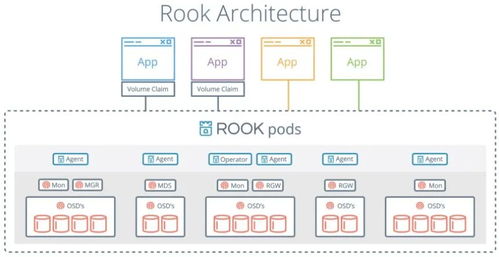
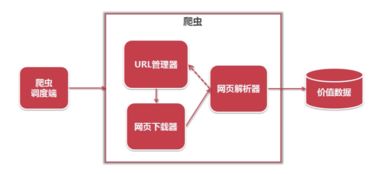
簡單爬蟲架構通常包含調度器、下載器、解析器、數據處理模塊和存儲模塊五個核心組件。其中,數據處理和存儲支持服務直接決定了爬蟲系統的可用性和擴展性。數據處理指對抓取的網頁進行清洗、去重、格式化和結構化處理的過程,而存儲支持服務則需保證數據的高效寫入、查詢和管理。
二、數據處理的關鍵技術
- 數據清洗:去除網頁中的無關信息,如廣告、版權聲明和HTML標簽。借助正則表達式或BeautifulSoup等工具實現。
- 數據去重:通過布隆過濾器或哈希算法避免重復采集,有效節省存儲資源。
- 結構化轉換:將非結構化的網頁內容轉化為結構化的JSON、CSV或數據庫記錄,便于后續分析使用。
三、存儲支持服務的實現方式
- 文件存儲:適用于小規模數據,將處理后的數據保存為本地文件,如CSV、JSON或TXT格式。
- 數據庫存儲:關系型數據庫(如MySQL)適用于結構化數據的快速查詢,非關系型數據庫(如MongoDB)則更擅長存儲半結構化的網頁內容。
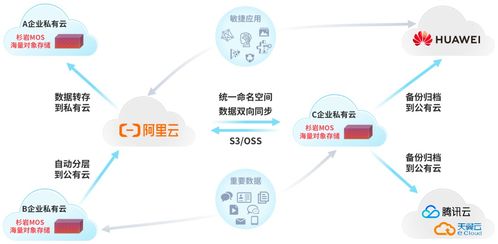
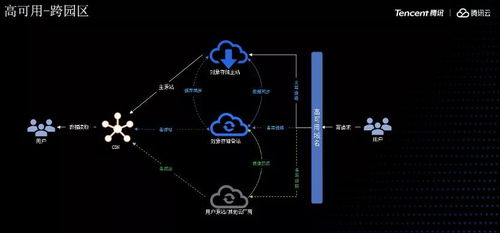
- 分布式存儲:當數據量較大時,采用HDFS或云存儲(如AWS S3)提供高可用性和可擴展性。
四、優化策略與實踐建議
- 異步處理:采用異步I/O和消息隊列(如RabbitMQ)提高數據處理效率。
- 緩存機制:將頻繁訪問的數據存入Redis等緩存系統,減輕數據庫壓力。
- 容錯設計:通過斷點續傳和數據備份機制確保系統在異常情況下的穩定性。
五、總結
簡單爬蟲架構中的數據處理和存儲支持服務是保障數據質量和系統性能的核心環節。合理選擇技術方案,結合異步處理和分布式存儲,能夠顯著提升爬蟲系統的整體效率與可靠性。隨著人工智能和大數據技術的發展,智能化的數據處理與存儲服務將成為爬蟲架構演進的重要方向。